Singapore, July 04, 2025 (GLOBE NEWSWIRE) — In September 2024, Skywork first open-sourced the Skywork-Reward series models and related datasets. Over the past nine months, these models and data have been widely adopted by the open-source community for research and practice, with over 750,000 cumulative downloads on the HuggingFace platform, helping multiple frontier models achieve excellent results in authoritative evaluations such as RewardBench.
On July 4, 2025, Skywork continues to open-source the second-generation reward models – the Skywork-Reward-V2 series, comprising 8 reward models based on different base models of varying sizes, with parameters ranging from 600 million to 8 billion. These models have achieved top rankings across seven major mainstream reward model evaluation benchmarks.
Skywork-Reward-V2 Download Links
HuggingFace: https://huggingface.co/collections/Skywork/skywork-reward-v2-685cc86ce5d9c9e4be500c84
GitHub: https://github.com/SkyworkAI/Skywork-Reward-V2
Technical Report: https://arxiv.org/abs/2507.01352
Reward models play a crucial role in the Reinforcement Learning from Human Feedback (RLHF) process. In developing this new generation of reward models, we constructed a hybrid dataset called Skywork-SynPref-40M, containing a total of 40 million preference pairs.
To achieve large-scale, efficient data screening and filtering,Skywork specially designed a two-stage human-machine collaborative process that combines high-quality human annotation with the scalable processing capabilities of models. In this process, humans provide rigorously verified high-quality annotations, while Large Language Models (LLMs) automatically organize and expand based on human guidance.
Based on the above high-quality hybrid preference data, we developed the Skywork-Reward-V2 series, which demonstrates broad applicability and excellent performance across multiple capability dimensions, including general alignment with human preferences, objective correctness, safety, resistance to style bias, and best-of-N scaling capability. Experimental validation shows that this series of models achieved the best performance on seven mainstream reward model evaluation benchmarks.

01 Skywork-SynPref-40M: Human-Machine Collaboration for Million-Scale Human Preference Data Screening
Even the most advanced current open-source reward models still perform inadequately on most mainstream evaluation benchmarks. They fail to effectively capture the subtle and complex characteristics of human preferences, particularly when facing multi-dimensional, multi-level feedback.
Additionally, many reward models tend to excel on specific benchmark tasks but struggle to transfer to new tasks or scenarios, exhibiting obvious “overfitting” phenomena. Although existing research has attempted to improve performance through optimizing objective functions, improving model architectures, and recently emerging Generative Reward Models, the overall effectiveness remains quite limited.
Meanwhile, models represented by OpenAI’s o-series and DeepSeek-R1 have promoted the development of “Reinforcement Learning with Verifiable Reward (RLVR)” methods, using character matching, systematic unit testing, or more complex multi-rule matching mechanisms to determine whether model-generated results meet preset requirements.
While such methods have high controllability and stability in specific scenarios, they essentially struggle to capture complex, nuanced human preferences, thus having obvious limitations when optimizing open-ended, subjective tasks.
To address these issues, we believe that the current fragility of reward models mainly stems from the limitations of existing preference datasets, which often have limited coverage, mechanical label generation methods, or lack rigorous quality control.
Therefore, in developing the new generation of reward models, we not only continued the first generation’s experience in data optimization but also introduced more diverse and larger-scale real human preference data, striving to improve data scale while maintaining data quality.
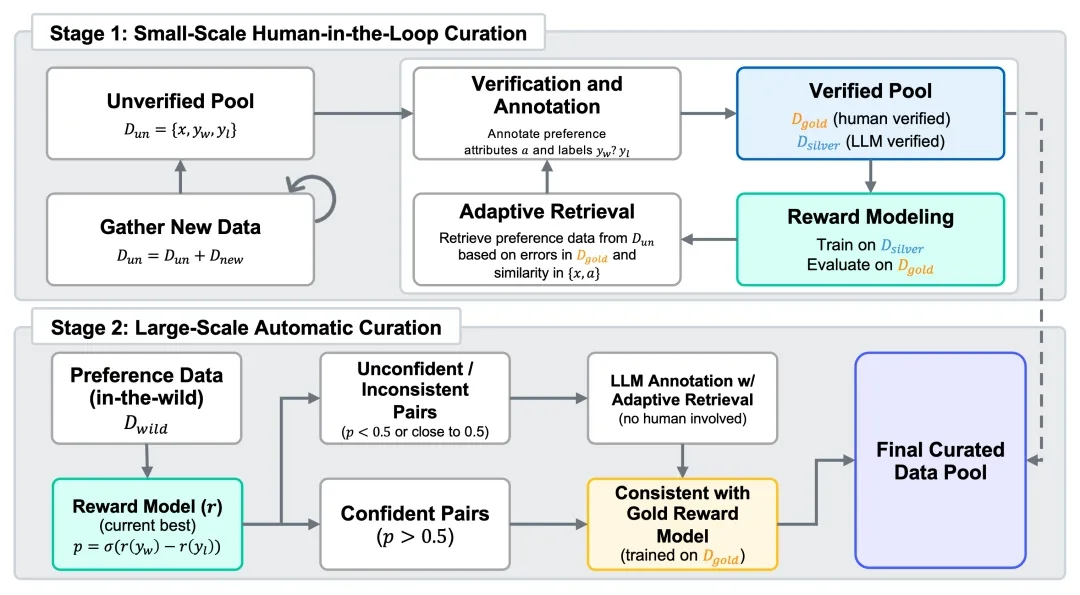
Consequently, Skywork proposes Skywork-SynPref-40M – the largest preference hybrid dataset to date, containing a total of 40 million preference sample pairs. Its core innovation lies in a “human-machine collaboration, two-stage iteration” data selection pipeline.
Stage 1: Human-Guided Small-Scale High-Quality Preference Construction
The team first constructed an unverified initial preference pool and used Large Language Models (LLMs) to generate preference-related auxiliary attributes such as task type, objectivity, and controversy. Based on this, human annotators followed a strict verification protocol and used external tools and advanced LLMs to conduct detailed reviews of partial data, ultimately constructing a small-scale but high-quality “gold standard” dataset as the basis for subsequent data generation and model evaluation.
Subsequently, we used preference labels from the gold standard data as guidance, combined with LLM large-scale generation of high-quality “silver standard” data, thus achieving data volume expansion. The team also conducted multiple rounds of iterative optimization: in each round, training reward models and identifying model weaknesses based on their performance on gold standard data; then retrieving similar samples and using multi-model consensus mechanisms for automatic annotation to further expand and enhance silver standard data. This human-machine collaborative closed-loop process continues iteratively, effectively improving the reward model’s understanding and discrimination of preferences.
Stage 2: Fully Automated Large-Scale Preference Data Expansion
After obtaining preliminary high-quality models, the second stage turns to automated large-scale data expansion. This stage no longer relies on manual review but uses trained reward models to perform consistency filtering:
- If a sample’s label is inconsistent with the current optimal model’s prediction, or if the model’s confidence is low, LLMs are called to automatically re-annotate;
- If the sample label is consistent with the “gold model” (i.e., a model trained only on human data) prediction and receives support from the current model or LLM, it can directly pass screening.
Through this mechanism, the team successfully screened 26 million selected data points from the original 40 million samples, achieving a good balance between preference data scale and quality while greatly reducing the human annotation burden.
02 Skywork-Reward-V2: Matching Large Model Performance with Small Model Size
Compared to the previous generation Skywork-Reward,Skywork newly released Skywork-Reward-V2 series provides 8 reward models trained based on Qwen3 and LLaMA3 series models, with parameter scales covering from 600 million to 8 billion.
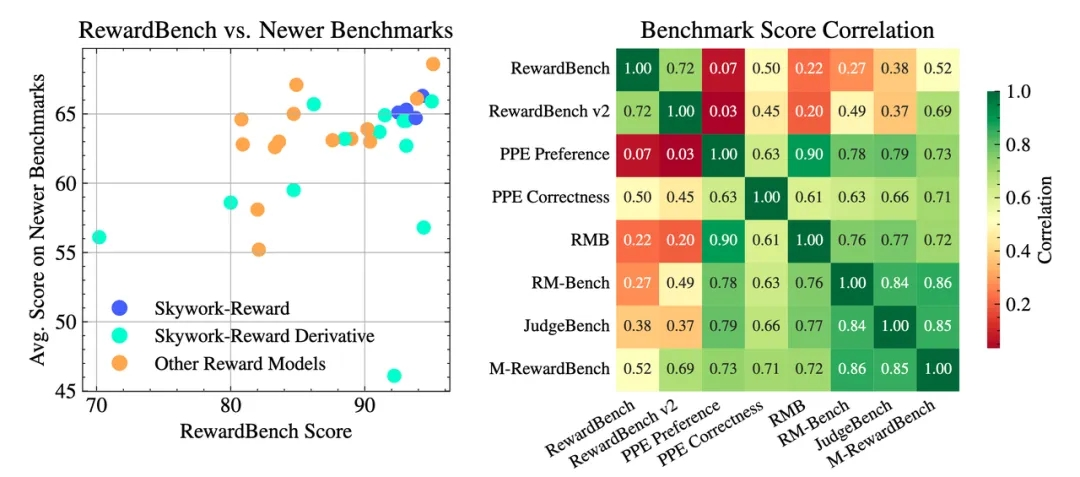
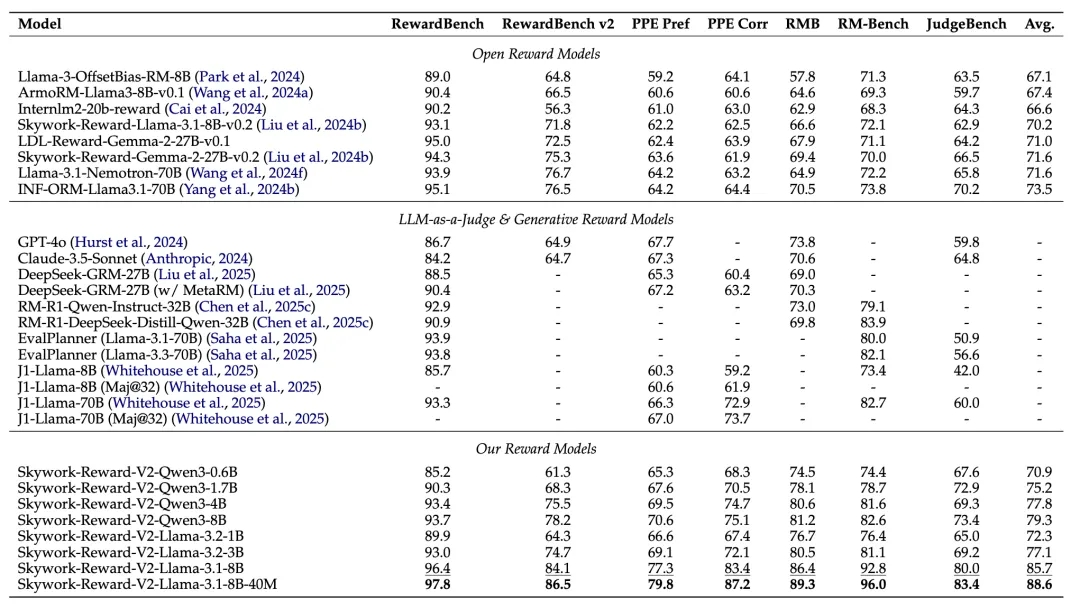
On seven mainstream reward model evaluation benchmarks including Reward Bench v1/v2, PPE Preference & Correctness, RMB, RM-Bench, and JudgeBench, the Skywork-Reward-V2 series comprehensively achieved current state-of-the-art (SOTA) levels.
Compensating for Model Scale Limitations with Data Quality and Richness
Even the smallest model, Skywork-Reward-V2-Qwen3-0.6B, achieves overall performance nearly matching the previous generation’s strongest model, Skywork-Reward-Gemma-2-27B-v0.2, on average. Furthermore, Skywork-Reward-V2-Qwen3-1.7B already surpasses the current open-source reward model SOTA – INF-ORM-Llama3.1-70B – in average performance. The largest scale model, Skywork-Reward-V2-Llama-3.1-8B, achieved comprehensive superiority across all mainstream benchmark tests, becoming the currently best-performing open-source reward model overall.
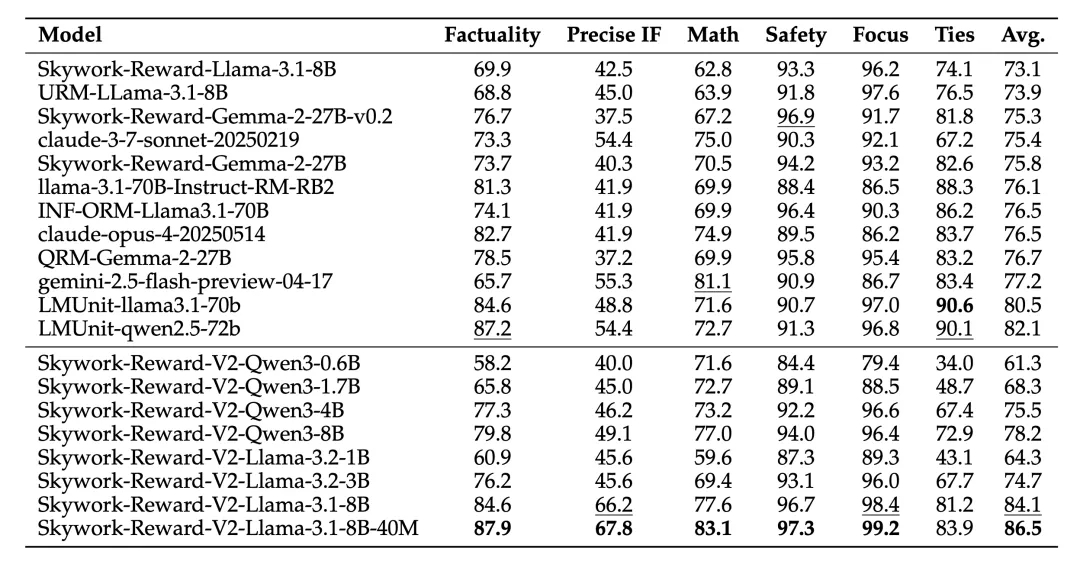
Broad Coverage of Multi-Dimensional Human Preference Capabilities
On general preference evaluation benchmarks (such as Reward Bench), the Skywork-Reward-V2 series outperforms multiple models with larger parameters (such as 70B) and the latest generative reward models, further validating the importance of high-quality data.
In objective correctness evaluation (such as JudgeBench and PPE Correctness), although slightly inferior to a few closed-source models focused on reasoning and programming (such as OpenAI’s o-series), it excels in knowledge-intensive tasks, surpassing all other open-source models.
Additionally, Skywork-Reward-V2 achieved leading results in multiple advanced capability evaluations, including Best-of-N (BoN) tasks, bias resistance capability testing (RM-Bench), complex instruction understanding, and truthfulness judgment (RewardBench v2), demonstrating excellent generalization ability and practicality.
On the more challenging RM-Bench, which focuses on evaluating models’ resistance to style preferences, the Skywork-Reward-V2 series also achieved SOTA performance
Highly Scalable Data Screening Process Significantly Improves Reward Model Performance
Beyond excellent performance in evaluations, the team also found that in the “human-machine collaboration, two-stage iteration” data construction process, preference data that underwent careful screening and filtering could continuously and effectively improve reward models’ overall performance through multiple iterative training rounds, especially showing remarkable performance in the second stage’s fully automated data expansion.
In contrast, blindly expanding raw data not only fails to improve initial performance but may introduce noise and negative effects. To further validate the critical role of data quality, we conducted experiments on a subset of 16 million data points from an early version. Results showed that training an 8B-scale model using only 1.8% (about 290,000) of the high-quality data already exceeded the performance of current 70B-level SOTA reward models. This result again confirms that the Skywork-SynPref dataset not only leads in scale but also has significant advantages in data quality.
03 Welcoming a New Milestone for Open-Source Reward Models: Helping Build Future AI Infrastructure
In this research work on the second-generation reward model Skywork-Reward-V2, the team proposed Skywork-SynPref-40M, a hybrid dataset containing 40 million preference pairs (with 26 million carefully screened pairs), and Skywork-Reward-V2, a series of eight reward models with state-of-the-art performance designed for broad task applicability.
We believe this research work and the continued iteration of reward models will help advance the development of open-source reward models and more broadly promote progress in Reinforcement Learning from Human Feedback (RLHF) research. This represents an important step forward for the field and can further accelerate the prosperity of the open-source community.
The Skywork-Reward-V2 series models focus on research into scaling preference data. In the future, the team’s research scope will gradually expand to other areas that have not been fully explored, such as alternative training techniques and modeling objectives.
Meanwhile, considering recent development trends in the field – reward models and reward shaping mechanisms have become core components in today’s large-scale language model training pipelines, applicable not only to RLHF based on human preference learning and behavior guidance, but also to RLVR including mathematics, programming, or general reasoning tasks, as well as agent-based learning scenarios.
Therefore, we envision that reward models, or more broadly, unified reward systems, are poised to form the core of AI infrastructure in the future. They will no longer merely serve as evaluators of behavior or correctness, but will become the “compass” for intelligent systems navigating complex environments, helping them align with human values and continuously evolve toward more meaningful goals.
Additionally, Skywork released the world’s first deep research AI workspace agents in May, which you can experience by visiting: skywork.ai